
3 micro learnings over this weekend :
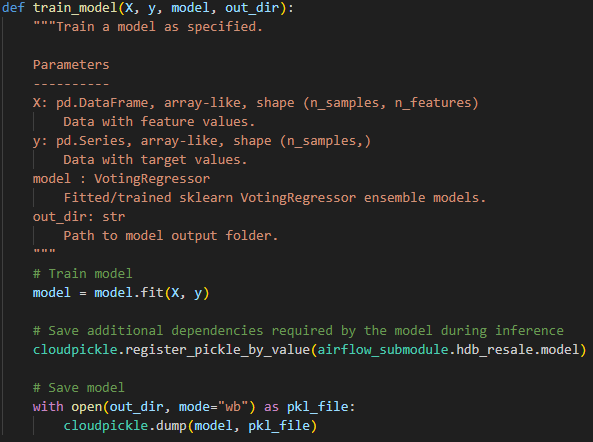
(1) cloudpickle works better than pickle in storing trained sklearn models
Have you ever proudly saved a trained sklearn model to be used for serving elsewhere, only for it to complain of missing imports or classes when you try to load it?
Other than making the imports or classes available in the model inference environment, I realise cloudpickle allows me to store the necessary model classes together with the trained model.
cloudpickle.register_pickle_by_value to the rescue.
(2) the purpose of using SQLAlchemy is to not write raw SQL codes
I have been using SQLAlchemy with pandas to interact with various databases for years.
However for some reasons that are unknown even to me, I never fully realise that SQLAlchemy is an ORM (object relational mapper) that helps abstract SQL operations into Python codes regardless of the underlying SQL dialect.
And I had been defining SQL tables manually without relying on SQLAlchemy’s MetaData and Table constructs.
(3) chatGPT is amazing in writing boilerplate code
I have to write tests for our local Airflow dev instance.
Instead of trying to dig through tutorials to find how to instantiate an Airflow DAG for testing purposes, I asked chatGPT to write them for me.
Granted I need to do minor modifications to the tests written by chatGPT, but it saved me at least 30 mins in googling for the boilerplate codes required.